Jonathan McDowell: Sorting out backup internet #1: recursive DNS
 I work from home these days, and my nearest office is over 100 miles away, 3 hours door to door if I travel by train (and, to be honest, probably not a lot faster given rush hour traffic if I drive). So I m reliant on a functional internet connection in order to be able to work. I m lucky to have access to Openreach FTTP, provided by Aquiss, but I worry about what happens if there s a cable cut somewhere or some other long lasting problem. Worst case I could tether to my work phone, or try to find some local coworking space to use while things get sorted, but I felt like arranging a backup option was a wise move.
Step 1 turned out to be sorting out recursive DNS. It s been many moons since I had to deal with running DNS in a production setting, and I ve mostly done my best to avoid doing it at home too. dnsmasq has done a decent job at providing for my needs over the years, covering DHCP, DNS (+ tftp for my test device network). However I just let it forward to my ISP s nameservers, which means if that link goes down it ll no longer be able to resolve anything outside the house.
One option would have been to either point to a different recursive DNS server (Cloudfare s 1.1.1.1 or Google s Public DNS being the common choices), but I ve no desire to share my lookup information with them. As another approach I could have done some sort of failover of
I work from home these days, and my nearest office is over 100 miles away, 3 hours door to door if I travel by train (and, to be honest, probably not a lot faster given rush hour traffic if I drive). So I m reliant on a functional internet connection in order to be able to work. I m lucky to have access to Openreach FTTP, provided by Aquiss, but I worry about what happens if there s a cable cut somewhere or some other long lasting problem. Worst case I could tether to my work phone, or try to find some local coworking space to use while things get sorted, but I felt like arranging a backup option was a wise move.
Step 1 turned out to be sorting out recursive DNS. It s been many moons since I had to deal with running DNS in a production setting, and I ve mostly done my best to avoid doing it at home too. dnsmasq has done a decent job at providing for my needs over the years, covering DHCP, DNS (+ tftp for my test device network). However I just let it forward to my ISP s nameservers, which means if that link goes down it ll no longer be able to resolve anything outside the house.
One option would have been to either point to a different recursive DNS server (Cloudfare s 1.1.1.1 or Google s Public DNS being the common choices), but I ve no desire to share my lookup information with them. As another approach I could have done some sort of failover of resolv.conf when the primary network went down, but then I would have to get into moving files around based on networking status and that felt a bit clunky.
So I decided to finally setup a proper local recursive DNS server, which is something I ve kinda meant to do for a while but never had sufficient reason to look into. Last time I did this I did it with BIND 9 but there are more options these days, and I decided to go with unbound, which is primarily focused on recursive DNS.
One extra wrinkle, pointed out by Lars, is that having dynamic name information from DHCP hosts is exceptionally convenient. I ve kept dnsmasq as the local DHCP server, so I wanted to be able to forward local queries there.
I m doing all of this on my RB5009, running Debian. Installing unbound was a simple matter of apt install unbound. I needed 2 pieces of configuration over the default, one to enable recursive serving for the house networks, and one to enable forwarding of queries for the local domain to dnsmasq. I originally had specified the wildcard address for listening, but this caused problems with the fact my router has many interfaces and would sometimes respond from a different address than the request had come in on.
/etc/unbound/unbound.conf.d/network-resolver.conf
server:
interface: 192.0.2.1
interface: 2001::db8:f00d::1
access-control: 192.0.2.0/24 allow
access-control: 2001::db8:f00d::/56 allow
/etc/unbound/unbound.conf.d/local-to-dnsmasq.conf
server:
domain-insecure: "example.org"
do-not-query-localhost: no
forward-zone:
name: "example.org"
forward-addr: 127.0.0.1@5353
I then had to configure dnsmasq to not listen on port 53 (so unbound could), respond to requests on the loopback interface (I have dnsmasq restricted to only explicitly listed interfaces), and to hand out unbound as the appropriate nameserver in DHCP requests - once dnsmasq is not listening on port 53 it no longer does this by default.
/etc/dnsmasq.d/behind-unbound
interface=lo
port=5353
dhcp-option=option6:dns-server,[2001::db8:f00d::1]
dhcp-option=option:dns-server,192.0.2.1
With these minor changes in place I now have local recursive DNS being handled by unbound, without losing dynamic local DNS for DHCP hosts. As an added bonus I now get 10/10 on Test IPv6 - previously I was getting dinged on the ability for my DNS server to resolve purely IPv6 reachable addresses. Next step, actually sorting out a backup link.











 Those of you who haven t been in IT for far, far too long might not know that next month will be the 16th(!) anniversary of the
Those of you who haven t been in IT for far, far too long might not know that next month will be the 16th(!) anniversary of the 
 They're called The Usual Suspects for a reason, but sometimes, it really is Keyser S ze
They're called The Usual Suspects for a reason, but sometimes, it really is Keyser S ze

 The Debian Project Developers will shortly vote for a new Debian Project Leader
known as the DPL.
The DPL is the official representative of representative of The Debian Project tasked with managing the overall project, its vision, direction, and finances.
The DPL is also responsible for the selection of Delegates, defining areas of
responsibility within the project, the coordination of Developers, and making
decisions required for the project.
Our outgoing and present DPL Jonathan Carter served 4 terms, from 2020
through 2024. Jonathan shared his last
The Debian Project Developers will shortly vote for a new Debian Project Leader
known as the DPL.
The DPL is the official representative of representative of The Debian Project tasked with managing the overall project, its vision, direction, and finances.
The DPL is also responsible for the selection of Delegates, defining areas of
responsibility within the project, the coordination of Developers, and making
decisions required for the project.
Our outgoing and present DPL Jonathan Carter served 4 terms, from 2020
through 2024. Jonathan shared his last  A short status update of what happened on my side last month. I spent
quiet a bit of time reviewing new, code (thanks!) as well as
maintenance to keep things going but we also have some improvements:
Phosh
A short status update of what happened on my side last month. I spent
quiet a bit of time reviewing new, code (thanks!) as well as
maintenance to keep things going but we also have some improvements:
Phosh
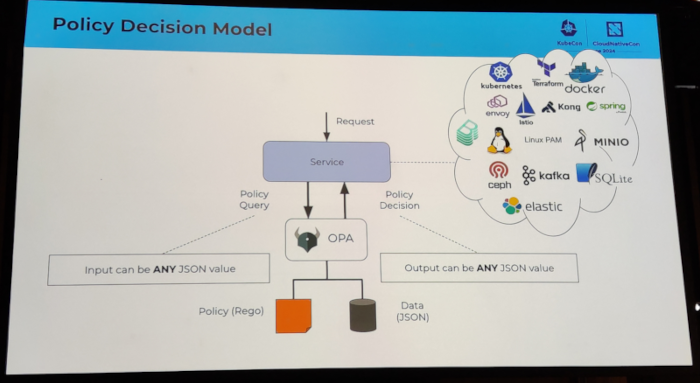 I attended several sessions related to authentication topics. I discovered the keycloak software, which looks very
promising. I also attended an Oauth2 session which I had a hard time following, because I clearly missed some additional
knowledge about how Oauth2 works internally.
I also attended a couple of sessions that ended up being a vendor sales talk.
See also:
I attended several sessions related to authentication topics. I discovered the keycloak software, which looks very
promising. I also attended an Oauth2 session which I had a hard time following, because I clearly missed some additional
knowledge about how Oauth2 works internally.
I also attended a couple of sessions that ended up being a vendor sales talk.
See also:
 I very recently missed some semantics for limiting the number of open connections per namespace, see
I very recently missed some semantics for limiting the number of open connections per namespace, see 


 The twentyfirst release of
The twentyfirst release of  The Amazon Kids parental controls are extremely insufficient, and I strongly advise against getting any of the Amazon Kids series.
The initial permise (and some older reviews) look okay: you can set some time limits, and you can disable anything that requires buying.
With the hardware you get one year of the Amazon Kids+ subscription, which includes a lot of interesting content such as books and audio,
but also some apps. This seemed attractive: some learning apps, some decent games.
Sometimes there seems to be a special Amazon Kids+ edition , supposedly one that has advertisements reduced/removed and no purchasing.
However, there are so many things just wrong in Amazon Kids:
The Amazon Kids parental controls are extremely insufficient, and I strongly advise against getting any of the Amazon Kids series.
The initial permise (and some older reviews) look okay: you can set some time limits, and you can disable anything that requires buying.
With the hardware you get one year of the Amazon Kids+ subscription, which includes a lot of interesting content such as books and audio,
but also some apps. This seemed attractive: some learning apps, some decent games.
Sometimes there seems to be a special Amazon Kids+ edition , supposedly one that has advertisements reduced/removed and no purchasing.
However, there are so many things just wrong in Amazon Kids:
 A welcome sign at Bangkok's Suvarnabhumi airport.
A welcome sign at Bangkok's Suvarnabhumi airport.
 Bus from Suvarnabhumi Airport to Jomtien Beach in Pattaya.
Bus from Suvarnabhumi Airport to Jomtien Beach in Pattaya.
 Road near Jomtien beach in Pattaya
Road near Jomtien beach in Pattaya
 Photo of a songthaew in Pattaya. There are shared songthaews which run along Jomtien Second road and takes 10 bath to anywhere on the route.
Photo of a songthaew in Pattaya. There are shared songthaews which run along Jomtien Second road and takes 10 bath to anywhere on the route.
 Jomtien Beach in Pattaya.
Jomtien Beach in Pattaya.
 A welcome sign at Pattaya Floating market.
A welcome sign at Pattaya Floating market.
 This Korean Vegetasty noodles pack was yummy and was available at many 7-Eleven stores.
This Korean Vegetasty noodles pack was yummy and was available at many 7-Eleven stores.
 Wat Arun temple stamps your hand upon entry
Wat Arun temple stamps your hand upon entry
 Wat Arun temple
Wat Arun temple
 Khao San Road
Khao San Road
 A food stall at Khao San Road
A food stall at Khao San Road
 Chao Phraya Express Boat
Chao Phraya Express Boat
 Banana with yellow flesh
Banana with yellow flesh
 Fruits at a stall in Bangkok
Fruits at a stall in Bangkok
 Trimmed pineapples from Thailand.
Trimmed pineapples from Thailand.
 Corn in Bangkok.
Corn in Bangkok.
 A board showing coffee menu at a 7-Eleven store along with rates in Pattaya.
A board showing coffee menu at a 7-Eleven store along with rates in Pattaya.
 In this section of 7-Eleven, you can buy a premix coffee and mix it with hot water provided at the store to prepare.
In this section of 7-Eleven, you can buy a premix coffee and mix it with hot water provided at the store to prepare.
 Red wine being served in Air India
Red wine being served in Air India
 I am eager to incorporate your AI generated code into my software.
Really!
I want to facilitate making the process as easy as possible. You're already
using an AI to do most of the hard lifting, so why make the last step hard? To
that end, I skip my usually extensive code review process for your AI generated
code submissions. Anything goes as long as it compiles!
Please do remember to include "(AI generated)" in the description of your
changes (at the top), so I know to skip my usual review process.
Also be sure to sign off to the standard
I am eager to incorporate your AI generated code into my software.
Really!
I want to facilitate making the process as easy as possible. You're already
using an AI to do most of the hard lifting, so why make the last step hard? To
that end, I skip my usually extensive code review process for your AI generated
code submissions. Anything goes as long as it compiles!
Please do remember to include "(AI generated)" in the description of your
changes (at the top), so I know to skip my usual review process.
Also be sure to sign off to the standard
 Closing arguments in the trial between various people and
Closing arguments in the trial between various people and